
Sina Masoumzadeh Sayyar
When was the last time you were worried about opening the water tap and having no water coming out of it? Or disgusted by the smell of wastewater because a pipe was blocked or broken in your neighbourhood? Most of us take the 24/7 functioning of water and wastewater systems for granted, blissfully unaware of the complex, underground network of pipes that keep our cities alive. Pipe breaks and network malfunctions are now getting so rare, especially in developed countries, that a pipe break, which used to be a less important, rather commonly happening matter, could lead to news articles with TV coverage!
I like to imagine the complicated system of pipes as the veins of a city: one carrying fresh, rejuvenating water and the other carrying used water. Disruptions in their functionality are tantamount to vascular diseases in humans (see, for example, this incident), and thus, they need constant attention to keep the functioning of the components reliable.
The expansion of these networks started with the tremendous growth of cities in North America and Europe. These networks were built mostly during the mid-20th century, and now, they are reaching a stage where massive renovations are required due to the pipes reaching the end of their lifespan. Renovation costs amount to billions of euros, and a delayed renovation of a faulty wastewater pipe, aside from disturbing everyday life and endangering public health, can cause serious environmental issues such as soil and groundwater pollution. The task seems clear: use limited financial resources efficiently, plan, and prevent dire consequences of failure. As straightforward as the task might seem, in practice, it is utterly complex. Based on parts of my PhD research, I will discuss some of the intricacies of managing these valuable and vital assets, my beloved pipes!
From Reactive to Proactive Management
There is no resting time for the water utility (the organisation responsible for water supply and wastewater collection) to manage the assets. From the moment a network expansion is conceived, managing the assets starts. Asset management is by no means a new and modern concern. However, how assets are managed has changed drastically. Traditionally, water utilities took a reactive approach, waiting for failures to happen before repairing or replacing pipes. Although this approach can still be spotted in practice even nowadays, utilities are now adopting a more proactive approach. In simple terms, they aim to prevent failures by renovating the pipes before they fail. But which pipes should be renovated and when? This is the million-dollar question at the heart of modern water and wastewater network asset management.
Like any other engineering field, we need models that mimic the deterioration process of pipes and predict when a pipe will fail to make informed plans. Physical (deterministic) models have been developed over the years, but the slow nature of the deterioration process and varying characteristics of wastewater are tough obstacles to understanding the exact process for model calibration. Pipe defects happen over the years and for a variety of reasons, emerging in different forms (like corrosion, different types of cracks, deformations, etc.). Monitoring pipes for extended periods and accounting for varying wastewater characteristics make this process even more difficult and expensive. Many variables in wastewater can affect deterioration, such as chemical characteristics (like pH, sulfate concentration, and microbial activity) and physical characteristics (such as temperature and flow rate). Additionally, environmental conditions that pipes are exposed to, such as proximity to roads, trees, groundwater, and soil types, further complicate monitoring and modelling.
This is where data and data-driven models come to our aid. Data-driven models rely on various sources of information, such as past inspection data, environmental conditions and usage patterns (including chemical characteristics like pH and sulfate concentration and physical characteristics like temperature and flow rate), rather than directly modelling the deterioration process. These models can predict when a failure will occur without requiring an understanding of the exact mathematical or physical relationships between the causes of deterioration and the emerging defects. By using such approaches, we can skip directly modelling the deterioration phenomenon and instead focus on the relationships within the data. However, this is not as straightforward as it seems.
Challenges in Data Collection and Predictions
Before diving into the intricacies, it is essential to understand what kinds of data are used and how they are collected. Data is usually the current condition of the pipes, which is derived from sets of inspections. One prevalent inspection method is using Closed Circuit Television (CCTV) and zoom cameras to look inside the pipe and identify defects. The observed defects receive a severity score, usually from 1 (very mild) to 4(extremely severe), which aggregates into a condition class score for the pipe.
One primary challenge in predicting the lifespan of pipes stems from the inspection process itself. Inspections are time-consuming and resource intensive. If inspections do not cover the entire network and pipes are not selected randomly, the sample may not represent the entire network. Even if we manage to inspect the entire network quickly, the data only represents a snapshot in time, as each pipe is typically inspected just once. This limits our ability to observe how pipes deteriorate over time, making it difficult to calculate the probability of pipes transitioning between different stages of deterioration. Besides, even in an ideal scenario where each pipe is inspected multiple times, and all data is accurately recorded, the inherent subjectivity in the inspection process can introduce significant uncertainty in the analysis.
Predicting the lifespan of pipes involves survival or time-to-event analysis, which focuses on estimating the probability of an event (such as failure) occurring at different time steps. Given that our event of interest is a failure, this approach will basically help us find out how probable a failure is at any given time in the future.
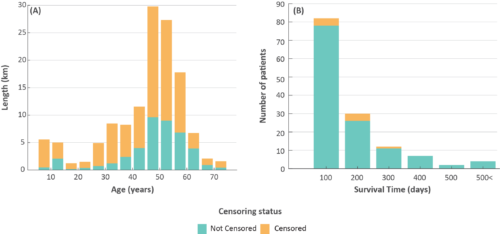
This type of analysis deals with the uncertainty of failure times, known as censoring in statistics. To make this concept clearer, consider an example from the medical field where censoring often occurs. Imagine a study aiming to measure the survival time of patients after a particular treatment. Some patients are still alive when the study ends, and their exact survival time is unknown at that point—these are censored observations. We only know that these patients survived up to the end of the study period, but we don’t know how long they will continue to live after. Similarly, for patients who might leave the study early, we know they survived up until their last check-up, but their exact survival time remains unknown—these observations are also censored. In both cases, we don’t have complete information about the exact time of the event (death), which parallels our pipe inspection scenario.
Censoring is inherent in the wastewater pipe inspection dataset because, during an inspection, a pipe is either found to be defective or not. Due to the slow nature of pipe deterioration, it is virtually impossible to observe a defect occurring in real time. If a pipe is found defective, the defect occurred at some point in the past. If a pipe is not defective, a failure or defect is expected to occur at an unknown future time.
For data-driven models, we need to know the values of the target (in our case, the time of failure of a pipe). We want the machines to learn to predict; in predicting the lifespan of the pipes, that is the only thing we do not know. This amount of uncertainty in the target value is indeed undesirable, but it is not entirely hopeless. There are methods to reduce the adverse effects of uncertainties due to censored data when using machine learning models. Some have modified the logic of the model to incorporate uncertainties and use survival analysis instead of traditional statistical analysis assumptions. Others have pre-processed the data to limit the effects of censoring. I am not here to discuss which is better or worse but to highlight that each problem is unique, and careful consideration is necessary when choosing a method to solve it.
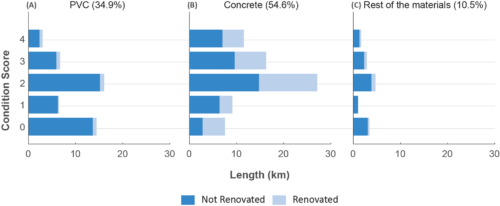
Furthermore, there is an interesting situation concerning wastewater networks, and we cannot say for sure what the endpoint of a pipe’s lifespan is. You might say that, well, it is obvious! The useful life of a pipe ends when it is severely defective and is renovated. Of course, this is absolutely right, yet data analysis showed that renovation decisions do not necessarily coincide with the severity of the defects Figure 2; there are considerable lengths of pipes in defective and severely defective conditions (condition classes 3 and 4) that have not been renovated yet. This is understandable, as renovation projects are not fast-paced and easy to execute. Interestingly, some pipes in good or non-defective states (condition scores of 1 and 0) have been renovated.
So, in adopting any method developed to address time-to-event analysis in wastewater network lifespan prediction, we needed to answer two questions: 1) How can we reduce censoring and its effects? 2) What is failure?
In answering the first question, we created smaller prediction intervals rather than using the entire lifespan of the pipes. In our study, we used 20-year prediction intervals to limit the effect of censoring. Breaking down the prediction interval reduces censoring since it helps us benefit from observations that would have been censored (i.e., we will not know whether it will survive or not). For instance, if we inspect a pipe after 50 years of its construction and find it in good condition, since we do not know when the failure will happen, the observation is censored. However, we can say with certainty that the pipe was in good condition during these 50 years, and thus, for example, a prediction interval of 20 to 40 years is not a censored observation but a non-occurring event. Furthermore, we used the inverse probability of censoring to weight the data to help the models account for the censoring. To answer the second question (the definition of failure), we trained models for both event types, ending up with two sets of events: one predicting the deterioration process of the pipe and one predicting whether or not a renovation decision will be made for a pipe by the utility.
You can find detailed descriptions of the methods and results in our preprint [2]. In short, we can state that our proposed methodology increases the accuracy of almost any type of machine learning model significantly. However, what we endorse is not the exact approach we took. It is a fact that exact method adoption is not the way of innovative problem-solving.
When selecting tools to solve our problems, it’s crucial to carefully consider their suitability and the context of their original development. Assumptions made during the initial creation of these tools may not hold for our specific needs and could lead to inaccurate interpretations if not examined thoroughly. Additionally, we must recognise that our accuracy requirements may differ significantly from those in other fields. As a result, we might need to modify the metrics we use to evaluate our models to fit our unique circumstances better.
In conclusion, thoughtful adaptation and a deep understanding of both the tools and the problems at hand are essential for effective problem-solving across any field. Incorporating expert knowledge is crucial, as it provides valuable insights that can significantly enhance the accuracy and applicability of models and methods. This mindful approach can lead to more reliable predictions, better decision-making processes, and ultimately, more resilient and effective solutions. But you might ask, what about the question I asked in the title? You will probably hate me for this, but the answer is: it depends. While some may question the reliability of data-driven approaches, the real challenge often lies not with the methods themselves but with the quality and comprehensiveness of the data. This is the same data that will be used to make renovation decisions anyway. In my opinion, having a moderately accurate model is always better than relying solely on a “gut feeling” since we can continuously refine and improve the model. Some people, even you, dear reader, might disagree with me. But who can really judge?
 Sina Masoumzadeh Sayyar is a doctoral researcher at Aalto University. He holds a Master’s degree in Civil Engineering and a strong passion for data science. His research focuses on data-driven asset management of water and wastewater networks, aiming to integrate modern analytics into infrastructure decision-making for more resilient and sustainable cities.
Sina Masoumzadeh Sayyar is a doctoral researcher at Aalto University. He holds a Master’s degree in Civil Engineering and a strong passion for data science. His research focuses on data-driven asset management of water and wastewater networks, aiming to integrate modern analytics into infrastructure decision-making for more resilient and sustainable cities.
References:
[1] Kalbfleisch. The Statistical Analysis of Failure Time Data, 2nd Edition. 2nd edition. Hoboken, N.J: Wiley-Interscience; 2002.
[2] Masoumzadeh Sayyar S, Kummu M, Mellin I, Tscheikner-Gratl F, Laakso T. Wastewater network assets’ lifespan prediction: can we modify the machine learning algorithms to fit the purpose? 2024. https://doi.org/10.2139/ssrn.4878532.